
Une introduction à l’apprentissage automatique
L’apprentissage machine ou apprentissage automatique est un domaine particulier de l’intelligence artificielle qui applique un processus informatique d’extraction de résultats que l’utilisateur cherche à analyser en fonction d’un objectif. Les méthodes utilisées peuvent être extrêmement diverses, mais concernent essentiellement des techniques issues de processus d’analyse statistique, ou de mise en œuvre de réseaux de neurones artificiels, simulés par un processus informatique 1.
Ces techniques sont profondément différentes des approches informatiques traditionnelles. En effet dans ces dernières, le résultat des algorithmes est déterminé par le résultat de calculs dont on connait les tenants et les aboutissants. Dans les processus d’apprentissage automatique, le résultat dépend d’un apprentissage lui-même dépendant de données dont on extrait le comportement particulier pour le généraliser à une classe de problèmes : par exemple, la reconnaissance de “chats” sur une image dépend d’une base de connaissance tirée de multiples photos de cet animal.

Le caractère à la fois relativement “nouveau” et inédit de ces techniques permet de comprendre que celles-ci sont en perpétuelles évolutions, et que les résultats qu’elles permettent d’obtenir sont eux même en révolution permanente. Les algorithmes que nous évoquerons sont les “briques de bases” telles qu’elles sont actuellement conçues. Mais elles sont en perpétuelle évolution du fait qu’on invente en permanence à la fois de nouvelles variations autour des “briques de bases” constituant le squelette des applications possibles, mais aussi de nouvelles organisations possibles de ces “briques de bases”. D’où des mutations perpétuelles qui constituent en même temps l’infinie richesse, mais aussi la difficulté du secteur.
L’apprentissage machine peut par exemple permettre à un ordinateur de mieux reconnaitre des objets hautement déformables, d’analyser les émotions révélées par un visage photographié ou filmé, d’analyser les mouvements, d’améliorer le positionnement automatique d’une caméra, etc.
L’apprentissage machine fait référence au développement et à l’implémentation de méthodes qui permettent à une machine d’évoluer grâce à un processus d’apprentissage et ainsi de remplir des tâches qu’il est difficile ou impossible de remplir par des moyens algorithmiques plus classiques. Elle vise à doter les machines de capacités habituellement attribuées à l’intelligence humaine.
Selon Arthur Samuel, 1959 : c’est donner la capacité aux machines d’apprendre sans les programmer explicitement.
Selon Tom Mitchell, 1997 : Un programme qui apprend est un programme qui tire profit d’une expérience E, par rapport à une famille de tâches T, pour une mesure d’efficacité P si son efficacité dans l’accomplissement des tâches de T, augmente après l’expérience E 2.
Historique
Pendant les années 90s et le début des années 2000, le développement de l’apprentissage machine s’est focalisé sur les algorithmes de machines à vecteurs supports et ceux d’agrégation de modèles. Pendant une relative mise en veilleuse du développement de la recherche sur les réseaux de neurones, leur utilisation est restée présente de même qu’une veille attendant le développement de la puissance de calcul et celle des grandes bases de données, notamment d’images.
Le renouveau de la recherche dans ce domaine est dû à Geoffrey Hinton, Yoshua Bengio et Yan le Cun qui a tenu à jour un célèbre site dédié à la reconnaissance des caractères manuscrits de la base MNIST. La liste des publications listées sur ce site témoigne de la lente progression de la qualité de reconnaissance, un taux d’erreur de 12% avec un simple perceptron à 1 couche jusqu’à moins de 0,3% en 2012 par l’introduction et l’amélioration incrémentale d’une couche de neurones spécifique appelée Convolutional Neural Network (CNN).
Types d’apprentissages machine
L’apprentissage machine permet à une machine d’évoluer par un processus systématique et d’effectuer des tâches pour lesquelles elle n’est pas explicitement programmée en apprenant avec des données. Ce procédé regroupe trois grandes méthodes d’apprentissage :
- Apprentissage supervisé ;
- Apprentissage non supervisé ;
- Apprentissage par renforcement.
Apprentissage supervisé
Il s’agit d’un apprentissage à partir d’exemples dans lesquels le résultat attendu est fourni avec les données d’entrée qui sont étiquetées avec les sorties souhaitées. Le système a une entrée et une sortie.
Le but de cette méthode est que l’algorithme puisse « apprendre » en comparant sa sortie réelle avec les sorties « enseignées » pour minimiser les erreurs de la fonction de coût. L’apprentissage supervisé utilise donc des modèles pour prédire les classes sur des données non étiquetées supplémentaires.
C’est la méthode la plus usitée à l’heure actuelle, elle permet de réaliser notamment un moteur de prédiction. La machine apprend « seule » par l’entraînement.
L’idée majeure de l’apprentissage est de trouver des relations de dépendance et de causalité entre plusieurs facteurs. On nourrit l’algorithme d’exemples dont les résultats sont connus par l’humain nourricier. Il note les différences entre prévisions et résultats corrects, puis affine ses prédictions par statistiques et probabilité jusqu’à ce qu’elles soient optimisées.
Les techniques telles que le SVM (Support Vector Machine) ou machine à vecteurs de support, le KNN (k-Nearest Neighbors) ou méthode des k plus proches voisins, les réseaux de neurones et l’apprentissage profond avec ses résultats spectaculaires appartiennent tous à la méthode d’apprentissage supervisé.
Les méthodes de l’apprentissage supervisé parmi les plus répandues seront présentées de façon plus ou moins succincte dans les paragraphes suivants. Ces paragraphes seront donc consacrés aux techniques algorithmiques : arbres binaires de décision et à celles plus directement issues de la théorie
de l’apprentissage machine : réseau de neurones et perceptron, support vaste marge (SVM) 1.

Apprentissage non supervisé
Aussi appelée apprentissage prédictif, la méthode d’apprentissage non supervisé consiste à apprendre à la machine le fonctionnement du monde, comme on le ferait avec un enfant. Le système dispose uniquement des données en entrée sans qu’on lui indique le résultat attendu en sortie (à la différence de l’apprentissage supervisé où l’on indique la réponse qui était attendue pour que la machine puisse apprendre). Il les classe selon des critères essentiellement statistiques qu’il appliquera pour discriminer les nouvelles entrées.

On ne guide pas la machine en lui donnant les bonnes ou mauvaises réponses en sortie dans la mesure où l’on ne maîtrise pas soi-même la réponse à donner : c’est ainsi que fonctionne le cerveau humain qui cherche à prédire le futur, d’où le terme apprentissage prédictif. Le cerveau apprend sur le monde en émettant des hypothèses qu’il vérifie petit à petit. Un exemple d’application de l’apprentissage non supervisé consiste à regrouper des clients d’une entreprise selon leurs comportements d’achat.
Apprentissage par renforcement
La méthode d’apprentissage par renforcement consiste à apprendre les actions à prendre, à partir d’expériences, de façon à optimiser une récompense quantitative au cours du temps. L’agent est plongé au sein d’un environnement, et prend ses décisions en fonction de son état courant. Il s’agit d’un apprentissage par essai/erreur. Le système a une entrée et teste des sorties avec la probabilité de gagner la récompense.
La méthode est lente et demande de faire tourner les options des millions de fois. On procède comme pour un animal qu’on dresse. On lui fait faire des choses et quand il réussit, on lui donne une récompense. Ainsi, on ne donne pas la réponse correcte à la machine, on attend qu’elle la produise.

Algorithmed’apprentissage
Outre les algorithmes mettant en jeu les “réseaux de neurones profonds” dont on parle beaucoup, bien d’autres algorithmes sont mis en œuvre et combinés, selon le domaine d’application et le secteur d’origine des concepteurs de ces algorithmes.
On peut citer dans les paragraphes suivant les principaux algorithmes utilisés par l’apprentissage machine.
Arbre de décisions
Un arbre de décision est un outil d’aide à la décision représentant un ensemble de choix sous la forme graphique d’un arbre. Les différentes décisions possibles sont situées aux extrémités des branches (les « feuilles » de l’arbre), et sont atteintes en fonction de décisions prises à chaque étape. L’arbre de décision est un outil utilisé dans des domaines variés tels que la sécurité, la fouille de données, la médecine, etc. Il a l’avantage d’être lisible et rapide à exécuter. Il s’agit de plus d’une représentation calculable automatiquement par des algorithmes d’apprentissage supervisé.
 Arbre de décision
Arbre de décision
Un avantage majeur des arbres de décision est qu’ils peuvent être calculés automatiquement à partir de bases de données par des algorithmes d’apprentissage supervisé. Ces algorithmes sélectionnent automatiquement les variables discriminantes à partir de données non structurées et potentiellement volumineuses. Ils peuvent ainsi permettre d’extraire des règles logiques de cause à effet (des déterminismes) qui n’apparaissaient pas initialement dans les données brutes.
En théorie des probabilités, un arbre aléatoire est un arbre défini en utilisant une loi de probabilité sur un ensemble d’arbres (au sens de graphe). Par exemple, un arbre aléatoire à n nœuds peut être choisi aléatoirement parmi tous les arbres à n nœuds suivant une loi de probabilité, par exemple avec une loi uniforme. Il existe d’autres manières de générer certains arbres particuliers (binaires par exemple).
Réseau de neurones artificiels
Un réseau de neurones artificiels, ou réseau neuronal artificiel, est un système dont la conception est à l’origine schématiquement inspirée du fonctionnement des neurones biologiques, et qui par la suite s’est rapproché des méthodes statistiques.
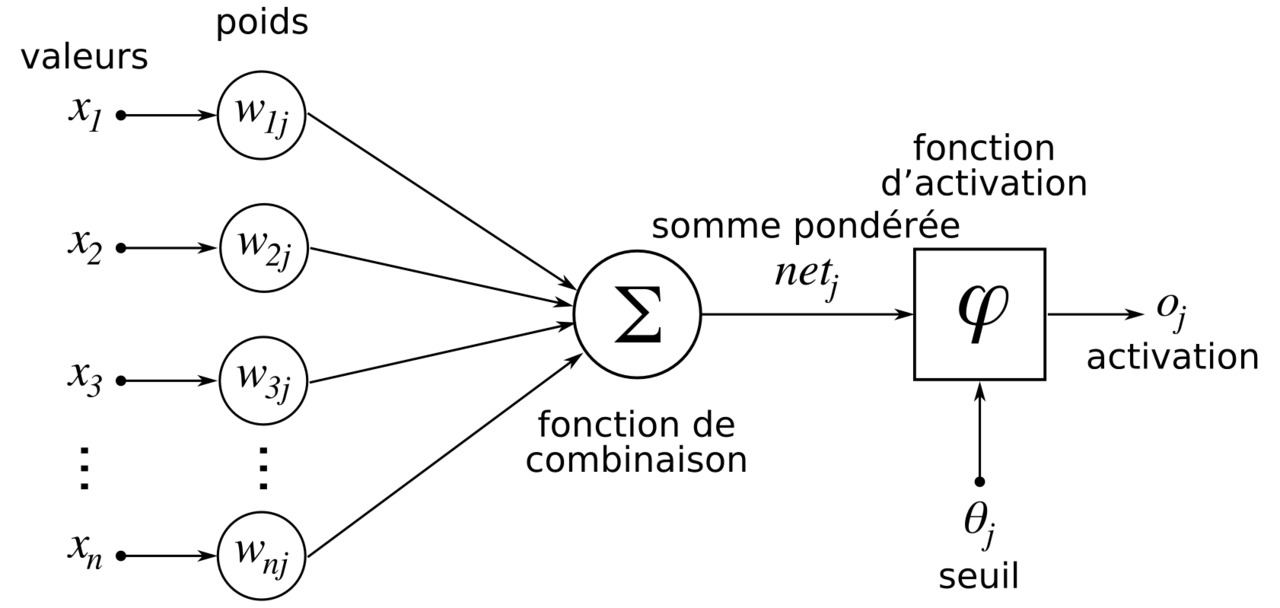
Les réseaux de neurones sont généralement optimisés par des méthodes d’apprentissage de type probabiliste, en particulier bayésien. Ils sont placés d’une part dans la famille des applications statistiques, qu’ils enrichissent avec un ensemble de paradigmes permettant de créer des classifications rapides, et d’autre part dans la famille des méthodes de l’intelligence artificielle auxquelles ils fournissent un mécanisme perceptif indépendant des idées propres de l’implémenteur, et fournissant des informations d’entrées au raisonnement logique formel.
Perceptron multicouche
Le perceptron multicouche (multilayer perceptron MLP) est un type de réseau neuronal formel organisé en plusieurs couches au sein desquelles une information circule de la couche d’entrée vers la couche de sortie uniquement ; il s’agit donc d’un réseau à propagation directe (feed forward). Chaque couche est constituée d’un nombre variable de neurones, les neurones de la dernière couche (dite « de sortie ») étant les sorties du système global.
Une couche d’entrée lit les signaux entrants, un neurone par entrée xj, une couche en sortie fournit la réponse du système. Selon les auteurs, la couche d’entrée qui n’introduit aucune modification n’est pas comptabilisée.

Une ou plusieurs couches cachées participent au transfert. Dans un perceptron, un neurone d’une couche cachée est connecté en entrée à chacun des neurones de la couche précédente et en sortie à chaque neurone de la couche suivante.
Le perceptron a été inventée en 1957 par Frank Rosenblatt au Cornell Aeronautical Laboratory, inspiré par la théorie cognitive de Friedrich Hayek et celle de Donald Hebb. Dans cette première version, le perceptron était alors monocouche et n’avait qu’une seule sortie à laquelle toutes les entrées sont connectées.
Réseau neuronal convolutif
Il existe un grand nombre de variables d’architectures profondes. La plupart d’entre eux sont dérivés de certaines architectures originales. Dans ce paragraphe nous allons choisir les réseaux de neurones convolutifs désignés par l’acronyme CNN, de l’anglais Convolutional Neural Network.
Les réseaux de neurones convolutifs sont à ce jour les modèles les plus performants pour classer des images. Ils comportent deux parties bien distinctes. En entrée, une image est fournie sous la forme d’une matrice de pixels. Elle a deux dimensions pour une image au niveau de gris. La couleur est représentée par une troisième dimension, de profondeur 3 pour représenter les couleurs fondamentales : rouge, vert, bleu.
La première partie d’un CNN est la partie convolutive à proprement parler. Elle fonctionne comme un extracteur de caractéristiques des images. Une image est passée à travers d’une succession de filtres, ou noyaux de convolution, créant de nouvelles images appelées cartes de convolutions. Certains filtres intermédiaires réduisent la résolution de l’image par une opération de maximum local. En fin, les cartes de convolutions sont mises à plat et concaténées en un vecteur de caractéristiques, appelé code CNN.
Ce code CNN en sortie de la partie convolutive est ensuite branché en entrée d’une deuxième partie, constituée de couches entièrement connectées (perceptron multicouche). Le rôle de cette partie est de combiner les caractéristiques du code CNN pour classer l’image. Pour une classification, la sortie est une dernière couche comportant un neurone par catégorie. Les valeurs numériques obtenues sont généralement normalisées entre 0 et 1, de somme 1, pour produire une distribution de probabilité sur les catégories.

Un avantage majeur des réseaux convolutifs est l’utilisation d’un poids unique associé aux signaux entrant dans tous les neurones d’un même noyau de convolution. Cette méthode réduit l’empreinte mémoire, améliore les performances et permet une invariance du traitement par translation.
Lorsque le volume d’entrée varie dans le temps (vidéo ou son), il devient intéressant de rajouter un paramètre de temporisation (delay) dans le paramétrage des neurones. On parlera dans ce cas de réseau neuronal à retard temporel (TDNN).
Comparés à d’autres algorithmes de classification de l’image, les réseaux de neurones convolutifs utilisent relativement peu de prétraitement. Cela signifie que le réseau est responsable de faire évoluer tout seul ses propres filtres (apprentissage sans supervision), ce qui n’est pas le cas d’autres algorithmes plus traditionnels. L’absence de paramétrage initial et d’intervention humaine est un atout majeur des CNN.
Support Vector Machine
Les machines à vecteurs de support ou Séparateurs à Vaste Marge (en anglais Support Vector Machine, SVM) sont un ensemble de techniques d’apprentissage supervisé destinées à résoudre des problèmes de discrimination note et de régression. Les SVM peuvent être utilisés pour résoudre des problèmes de discrimination, c’est-à-dire décider à quelle classe appartient un échantillon, ou de régression, c’est-à-dire prédire la valeur numérique d’une variable.

Apprentissage profond
L’apprentissage profond, plus précisément « apprentissage approfondi », et en anglais « deep learning », est un ensemble de méthodes d’apprentissage automatique tentant de modéliser avec un haut niveau d’abstraction des données grâce à des architectures articulées de différentes transformations non linéaires. Ces techniques ont permis des progrès importants et rapides dans les domaines de l’analyse du signal sonore ou visuel et notamment de la reconnaissance faciale, de la reconnaissance vocale, de la vision par ordinateur et du traitement automatisé du langage.
L’apprentissage profond fournit des algorithmes qui permettent à l’ordinateur d’apprendre les nombreux paramètres nécessaires à la réalisation de tâches utiles, sur des données purement numériques, mais aussi dans le monde physique via la robotique. Le sous-domaine de l’apprentissage profond est le plus porteur en ce moment, et propose des structures computationnelles inspirées de celles du cerveau, l’unité de base étant une version très schématisée d’un neurone implémenté de façon logicielle ou matérielle, et le traitement s’effectuant par couches de neurones interconnectées.
Le principe fondamental d’apprentissage profond consiste alors à ajuster progressivement les paramètres de chacun de ces neurones de façon à réduire l’erreur constatée par rapport à l’objectif attendu. Les systèmes les plus avancés à ce jour comportent jusqu’à 100 millions de neurones et des systèmes à 100 milliards de neurones, soit l’équivalent de nos cerveaux, sont attendus avant 2030.
L’apprentissage profond fait partie d’une famille de méthodes d’apprentissage automatique fondées sur l’apprentissage de modèles de données. Une observation (une image, p. ex.) peut être représentée de différentes façons par un vecteur de données, notamment en fonction de :
- L’intensité des pixels dont elle est constituée ;
- Ses différentes arêtes ;
- Ses différentes régions, aux formes particulières.
Certaines représentations et une bonne capacité d’analyse automatique des différenciations rendent la tâche d’apprentissage plus efficace.
Une des perspectives des techniques de l’apprentissage profond est le remplacement de certains travaux relativement laborieux, par des modèles algorithmiques d’apprentissage supervisé, non supervisé (c’est-à-dire ne nécessitant pas de connaissances spécifiques quant au problème étudié) ou encore par des techniques d’extraction hiérarchique des caractéristiques.
Les différentes architectures de l’apprentissage profond ont plusieurs champs d’application :
- La vision par ordinateur (reconnaissance de formes) ;
- La reconnaissance automatique de la parole ;
- Le traitement automatique du langage naturel ;
- La reconnaissance audio et la bio-informatique.
Articles Similaires

Ubuntu 24.04 LTS - Une version qui fait débat entre déception et enthousiasme
Ubuntu 24.04 LTS, “Noble Numbat”, a récemment été déployée, apportant son lot de nouveautés et de changements. Cette version suscite à la fois de l’enthousiasme et de la déception au sein de la communauté des utilisateurs et des développeurs. Déception et colère face à la gestion des paquets DEB Plusieurs utilisateur d’Ubuntu ont exprimé leur déception et colère face à la décision de Canonical, la société mère d’ Ubuntu, de favoriser les paquets Snap au détriment des paquets DEB.
Lire la Suite
Le concours de beauté Miss AI : un cauchemar dystopique ou le futur de la beauté ?
Dans un monde où la technologie et la beauté fusionnent, le concours de beauté Miss AI fait son apparition. Ce concours, organisé par The World AI Creator Awards, récompense les créateurs d’images et d’influenceurs générés par intelligence artificielle (IA). Mais qu’est-ce que cela signifie pour les standards de beauté et les femmes ? Le concours Miss AI est ouvert aux créateurs d’images et d’influenceurs générés par IA qui souhaitent montrer leur charme et leur compétence technique.
Lire la Suite
Le gouvernement du Salvador prend un coup dur : les hackers divulguent le code source et les accès VPN du portefeuille bitcoin national Chivo !
Le programme bitcoin du gouvernement du Salvador, Chivo, a été victime d’une série d’attaques informatiques ces derniers jours. Les hackers ont déjà divulgué les données personnelles de plus de 5 millions de Salvadoriens. Maintenant, les mêmes pirates informatiques ont publié des extraits du code source et des informations d’accès VPN du portefeuille bitcoin national Chivo sur un forum de hacking en ligne, CiberInteligenciaSV. Ceci est un coup dur pour El Salvador, qui lutte pour être un pionnier dans l’adoption du bitcoin.
Lire la Suite